

A regression test is a system-wide test that’s intended to ensure that a small change in one part of the system does not break existing functionality elsewhere in the system. It’s important because without regression testing, it’s quite possible to introduce intended fixes into a system that create more problems than they solve.
Let’s take a look at a fictitious example that illustrates what can happen when regression testing is not used.
What Could Possibly Go Wrong?
One day the manager of the Accounts Receivable Department at Acme Widgets uncovered a bug in the company’s financial system. It turns out that the module responsible for reporting overdue invoices was not listing all the overdue invoices. A Jira ticket was written up describing the bug along with instructions about how to replicate the problem. The bug was assigned to a developer who made the fix.
The developer followed company policy and unit tested the new code. The unit test proved beyond a shadow of a doubt that the fix worked as intended. (See Figure 1, below)
 Figure 1: Typically the scope of retesting code is at the unit test level.
Figure 1: Typically the scope of retesting code is at the unit test level.
Once the developer reported in Jira that the bug was fixed, QA took a look at the passing unit test to make sure that the developer followed the company’s code coverage policy. Also, the QA tester exercised the test system in which the new code was installed to make sure that fix worked as expected. The test code worked on the test system as expected.
The fix was released into production. So far, so good.
A week passes. Then a strange behavior occurs when the Accounting Department tries to run the company’s month-end P&L statement. Whenever the system tries to issue an Aging Report, the system times out. (An Aging Report separates and sums invoice amounts according to age -- current, 30 days past due, 60 days past due, 90 days past due, over 90 days.)
Pandemonium breaks out at Acme Widgets. Without its month-end P&L statement, the company doesn’t know if it’s making or losing money. The Accounting Department is upset. The system worked fine the previous month. Now it's broken. The Accounting Manager contacts the Software Development Manager to report the issue and seek remedy as soon as possible.
The Software Development Manager goes through Jira to locate tickets that indicate any code changes prior to running the end of month P&L statement. The Jira ticket for addressing the past due invoice problem glares out at him. Software Development Manager calls in the Tech Lead and together they go over the code and unit tests. All looks well, it seems. Then they call in QA Manager to get another set of eyes on the issue. On the surface, all seems well to the QA Manager too.
Then the QA Manager has a hunch. She takes a look at the unit test and notices that the test was run against a small test database that contained data for invoices from the first quarter of the year. That data was sufficient to replicate the error so the bug could be fixed and successfully unit tested. But, the code was never tested using production data.
The Tech Lead contacts the Developer who made the fix. They go over the fix together and discover that the change appeared benign when applied to the small dataset. The Tech Lead runs the code against a copy of production dataset. Turns out that the new code, which was encapsulated in a function, getPastDueInvoices(dueDate), takes 5 seconds to execute against production data.
The code fix took 1.5 seconds to run when unit tested. Thus, it seemed fine but in production, it wasn’t. The Accounting System was configured with a timeout period of 2 seconds against calls to the Invoice module. (See Figure 2.)
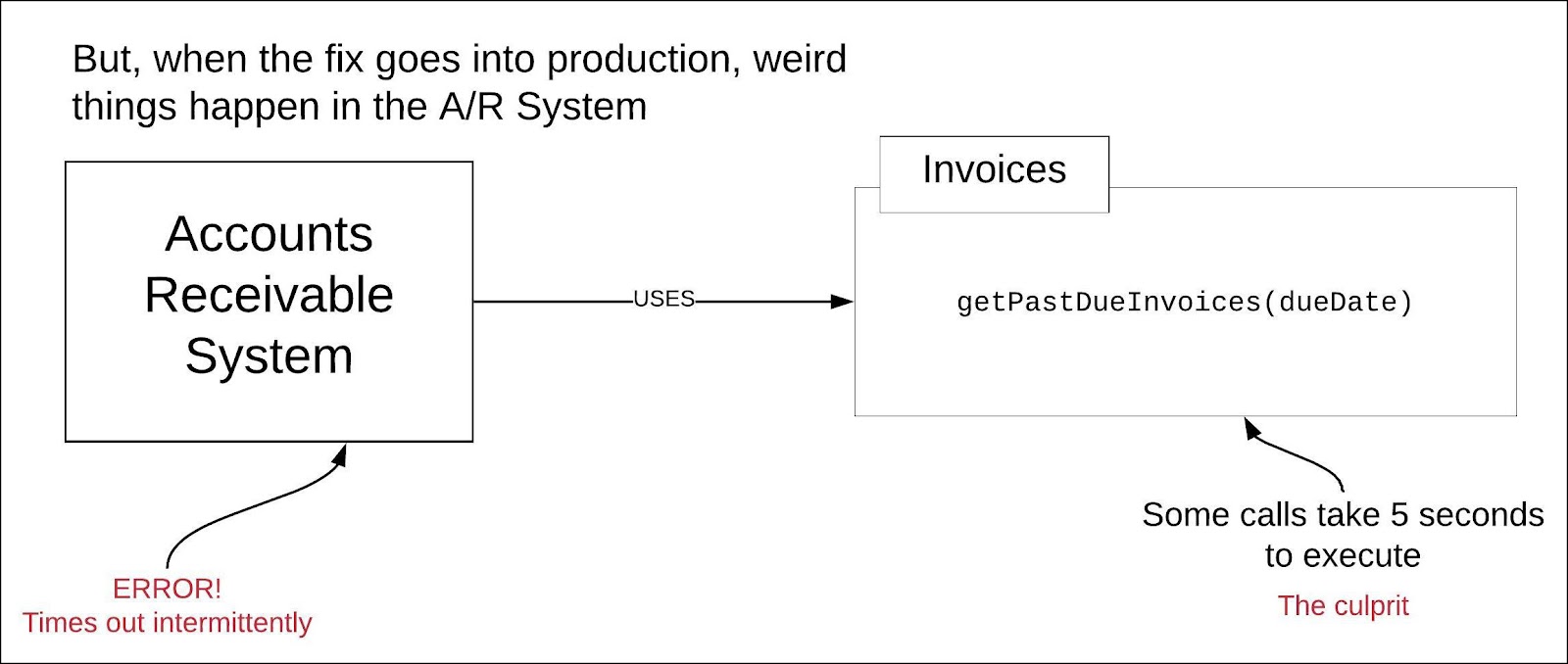
Figure 2: A regression test ensures that new code in one part of the system does not cause unwanted side effects in the system overall
It turns out the the Developer indeed retested the code fix by way of a unit test. And QA did a high-level inspection but no regression testing was performed. The fix worked to expectation under unit testing and yet it broke the system when running in production. Had the fix been incorporated into a system-wide regression test that used a copy of the data running in production, the chances are very good that the issue would have been discovered before the release to production. Thus, the value and importance of regression testing.
Regression testing is more than retesting
Regression testing is valuable. Sadly, sometimes a company will think it’s doing regression testing when actually it’s just doing retesting. Retesting is about making sure that a specific code change works according to expectation. Regression testing is about ensuring that the entire system works to expectation once a change has been introduced. As such, designing and implementing regression tests has a much broader scope of activity than retesting.
Typically, retesting occurs quickly, at or very near the time code is being created. Regression tests take place further along in the SDLC when more time is available to accommodate the longer timespan required to execute the testing. Yes, some retests can be quite complex and time-consuming, but nowhere near the length of time required to execute a comprehensive regression test. Remember, adequate regression testing means that all aspects of the system must be tested and just as importantly, monitored. Performing a regression test without adequate, system-wide monitoring in place turns the testing effort into a guessing game. As we demonstrated in the opening scenario, an error can occur in one part of the system, yet be caused by behavior in another part. Adequate monitoring gives you the insights into the system you need in order to determine problems and root causes.
Incorporating Regression Testing into the Iterative Model
The case for regression testing is strong. However, implementing one under Agile can be hard. The goal of Agile and DevOps is to get working software into hands of users as quickly as possible under short, fast release cycles. Yet, regression testing takes time, maybe more time than a single iteration can allow. So what’s to be done?
One solution is to stagger the regression testing between iterations. Figure 3 below shows a timeline of three iterations. A code version is released in each iteration. However, regression testing the code created during the iteration starts halfway into the iteration and continues into the following iteration. Starting regression testing halfway through an iteration allows test practitioners to uncover problems as new code “settles in” during the iteration. Then, fixes can be implemented and absorbed in the following iteration.
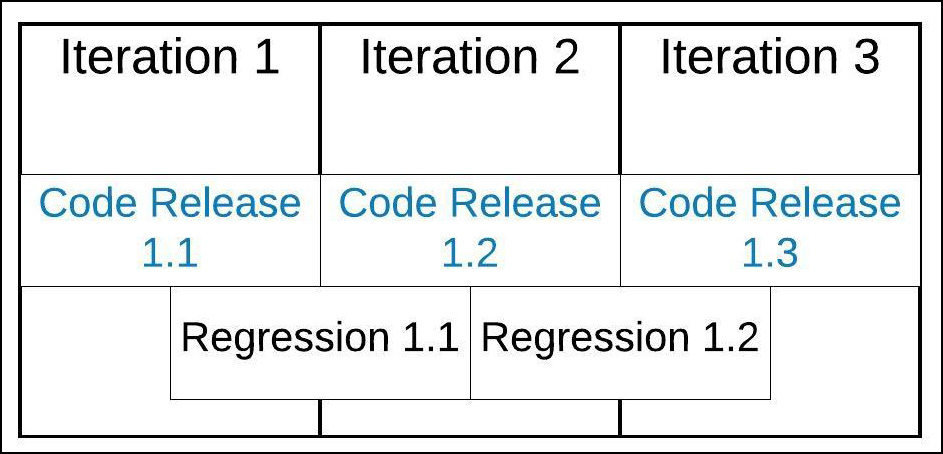
Figure 3: Staggering regression testing over iterations supports the Agile way of development yet allows adequate time for regression testing.
Confining regression testing to only the current version of code under development in an iteration runs the risk of creating a waterfall dynamic. Development teams could be brought to a standstill waiting for regression tests to complete before performing fixes. And then, once issues are uncovered and remedied by developers, regression testers would need to wait until the new code is available before further action can take place. Clearly, this “handoff and wait” pattern is antithetical to an Agile approach to software development. Staggering regression tests over iterations gives testers the time they need to perform the scope of testing required while allowing development staff to create new code in the meantime.
Putting It All Together
It’s rare for code to be perfect upon initial release. Modern software development has come to accept that releasing software is more about making it better over time than getting it right from the start.
This is not to say the companies just push code out the door and leave the quality of a release to chance. Quite the opposite. Forward-thinking companies go to great lengths to make it so that testing is conducted as a matter of habit throughout all stages of the Software Development Lifecycle. Also, forward-thinking companies understand that as systems get bigger and the speed by which software is created increases, the chances of side-effects emerging increases. Thus, companies that embrace comprehensive testing throughout the software development lifecycle place special emphasis on regression testing. Regression testing is the first and best line of defense for risk mitigation, and ensures that the code that makes up the parts of the software does indeed make the whole system better.
That's why mabl helps teams create automated tests for their applications, and automates regression testing. Using machine intelligence, mabl analyzes test output to monitor overall health degradation, visual changes, and performance slowdowns. It's free to try for 21 days at mabl.com.




