
There’s a saying that’s being thrown about in the software testing community. It goes like this: “A testing process without history, ain’t.”
According to Geoff Cooney, a software engineer at mabl,
“Test history reveals aspects of software quality that cannot be determined by any one test. The thing that comes to mind immediately is performance behavior: is my code speeding up, or slowing down? Also, given the prominence of eventual consistency when it comes to determining system state, determinism can be hard to come by at the systems level. A good test history can help identify truly flaky tests and provide context for tests that do fail.”
Geoff has it right. When it comes to historical reporting, information gathered from a single testing session is of no more value than the score of a single baseball game when it comes determining the standing of each team in the league. Without having the benefit of the historical data related to your tests, you lose visibility into the trends within and about the software quality. For example, is the current code making your software go faster or slower? Or, are the algorithms in the software losing accuracy? And, as Geoff points out above, as data integrity becomes increasingly subject to the dynamics of eventual consistency, the result of one test might be misleading. One test session might report failure, while ten others pass. The data we gather from test history provides the information necessary for the analysis of trends and probabilities relevant to software quality.
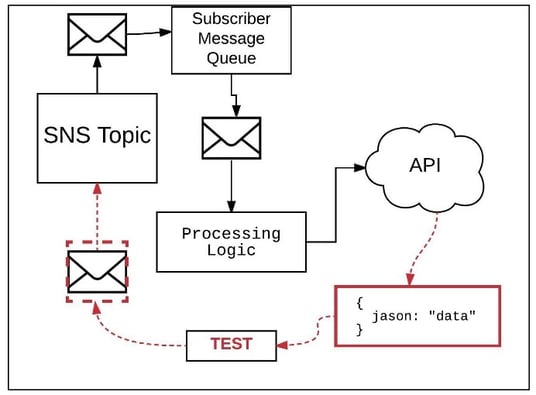
Allow me a share a case in point. A while back I was doing some development work that involved the extensive use of message queues. The underlying mechanics are as follows: a message queue subscribing to an AWS SNS topic receives a message that’s consumed by some application logic; the application logic in turn extracted data from the message and forwarded some of the data onto an API endpoint. (See Figure 1.)
Of course I had a test to verify my programming. The test sent a message to the SNS topic, waited for a predefined number of seconds and then looked for the subset of data that was supposed to be within the receiving API’s domain. (How the test gets the data from the API domain is another story, one that is not that relevant presently.)
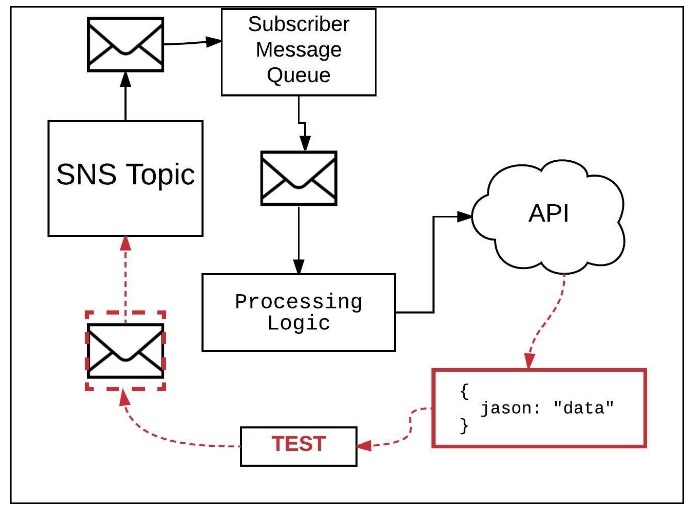
Figure 1: Without test history even simple tests can be misleading, particularly those subject to latency
The test failed every time I ran it within the test runner, in this case Mocha/Chai under Node.js. However, when I started doing manual inspection or ran the test code through a debugger, the tests passed. I suspected a latency problem between SNS and the AWS message queue on SQS. So, I moved the topic and subscribing queue to different a AWS region. Turns out I was right. The problem was latency. The code ran as expected in the alternate region. If you think my experience is frustrating, try expanding the issue to multiple developers and software testers trying to debug a regression test of this sort with ongoing commits happening in the background. It’s enough to drive even the most patient group of people to the edge.
Yet, these sort of things happen everyday. I do not have enough fingers and toes to count the number of developers and testers who have pulled their hair out battling latency problems. However, if test history was built into my testing process, I could have simply run my test X amount of times against an SNS/SQS combination in one region and then the same number of times against identical code in a different region. Comparing the history of results would have saved me an evening’s worth of heartache.
As you see from my example, the benefit of having a testing process that provides test history is apparent. Yet while most teams intuitively recognize the value of test history for metric reporting, many just compile test history manually over time into ad hoc reports, often intended for the eyes of management. However, supporting the detailed, ongoing aspects of test history such as code coverage trends, test counts overtime, stability metrics, etc… as part of the Software Testing Lifecycle requires planning. Also, making sure the data reflected in a test history is useful throughout the enterprise requires input from all the parties that have interest in the software, from design to release.
So, where do we start?
Not all Software Testing Reports are Historical
The best starting point is to understand that a test history is an aggregation of testing metrics gathered over two or more testing sessions. A testing session is the execution of a test or a suite of tests. Listing 1 below shows an example of a simple test suite of unit tests written in JavaScript for a Node.Js project.

Listing 1: A simple, typical unit test suite
Once a test session executes, we can report the result of the session in a variety of report formats. Figure 2 below shows a report that describes how many tests in the suite passed and how many failed.
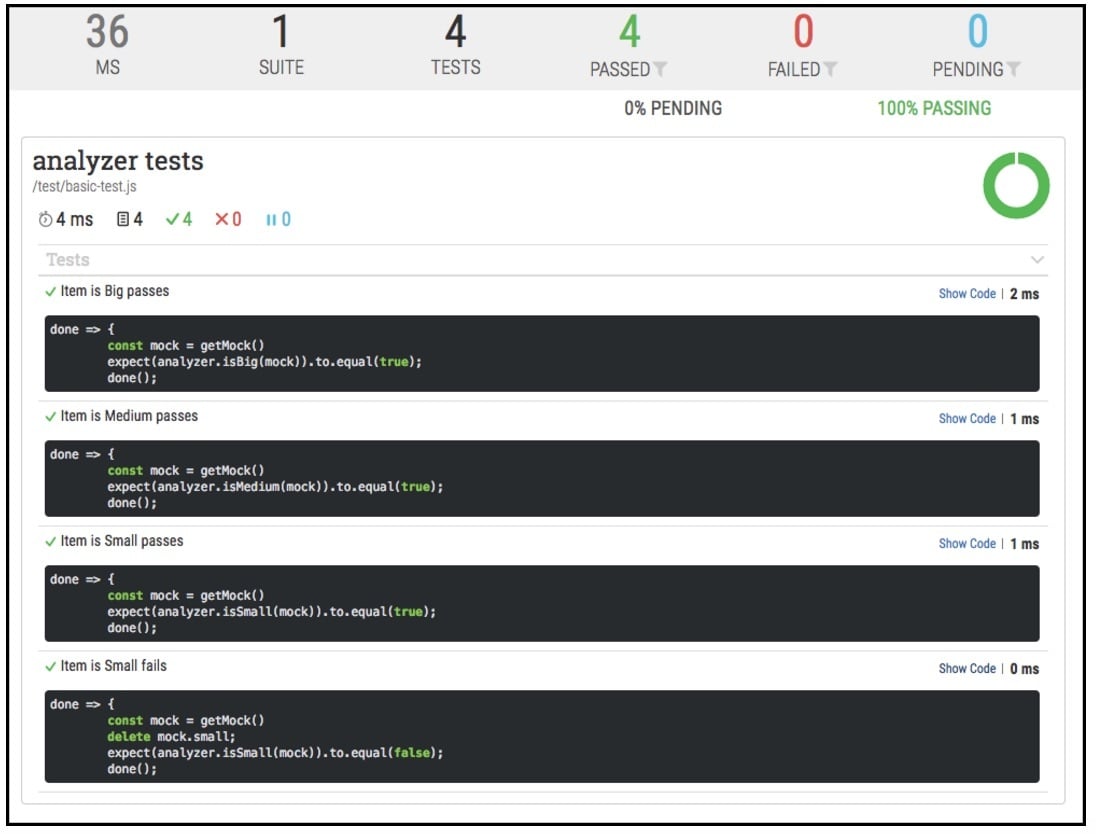
Figure 2. A Pass/Fail test report for a Node.js project using mochawesome.
The metrics reported in Figure 2 are the time it took for the suite to run, by test and overall. The report also shows the number of tests in the suite, the number passed, the number failed and the number pending.
Figure 3, belows shows a code coverage report created using the Istanbul project. The report is derived from information gathered using the test suite illustrated in Listing 1.
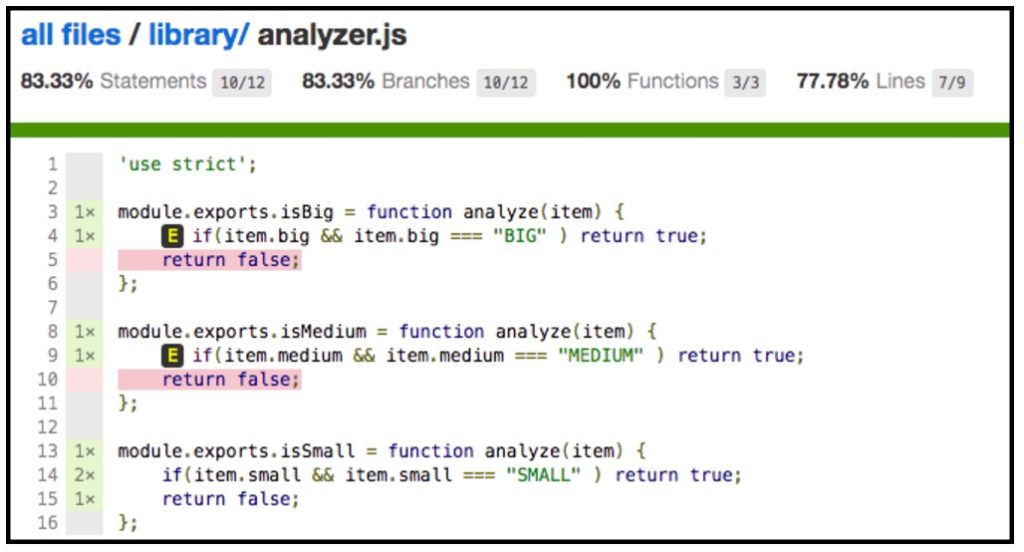
Figure 3: A coverage report shows the lines of code exercised by a set of tests
The coverage report in Figure 3 has a variety of metrics, most prominent are the lines of code exercised and not exercised by the test suite.
The important thing to understand is that while both reports are valid, they provide no historical information about the testing process.
As mentioned above, we need to aggregate information over many testing sessions in order to provide history.
Using Developer Tools to Create Test History
There are a few ways to approach implementing test history. Implementations will vary according to the level and type of testing you are doing. For example, you can use an off the shelf tool, such as unitTH for creating test history at the Java unit test level. Teamcity provides a test history feature for source code too. Azure integrates with Visual Studio Team Services to provide performance testing history. These are but a few of the tools available.
The benefit of using a pre-existing tool is that you save time and avoid reinventing the wheel. Yet there are times when even the most feature laden tool will fall short when it comes to meeting the need at hand. In such cases you might need to take a custom approach in order to create useful test histories.
Taking a Custom Approach
When it comes to considering a custom approach, one idea is to take advantage of cloud based logging services. For example, the test designer will bind test logging to a log service such as Logentries or Sumologic. Then the test designer will devise a way to send test results as log entries to the logging service. Once test result data is stored in the logging service, the test designers create historical reports using the data aggregation and reporting capabilities provided by the logging service.
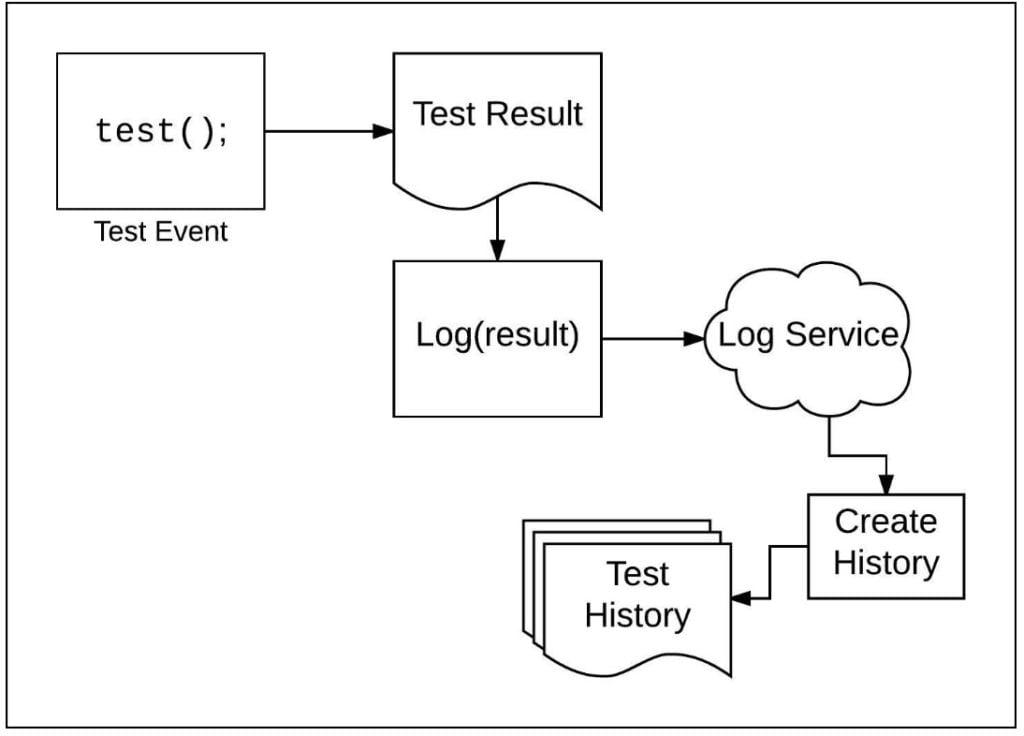
Figure 4: Using a logging service’s reporting capabilities provides a way to create a history of test results
One advantage of using a common logging service is that teams will often run tests against different environments. Being able to tag those environments and filter the log entries accordingly fits well with these tools’ strengths.
Correlation, the Next Frontier for Test History
There is little downside to ensuring your test processes support history. If you got nothing more than being able to determine trends and patterns in your software over time, you will still be way ahead of the game. However, where things get really begin to get interesting is when we combine histories from different parts of an application to determine correlation.
For example, imagine that that we have a front end test that shows failure in its history. Also, when we take a look that backend server logs, we see occurrences of failure. Consider the distinct frontend and backend histories gives us a limited insight. We know the frontend has problems and we know the server has errors intermittently. But, we do not get the full picture. However, when we start looking at the test results in terms of historical interaction between the different parts of the application, frontend and backend, we get a new perspective on matters.
Of course we need to have a way to tie the histories together. This is where using a logging service as a common repository of test data comes into play. We need to plan not only how to make the association but also how to find valid correlation. At the least we will need to come up with a tagging scheme that allows us to “join” the log entries from the different parts.
One way is to use a correlation identifier to bind together application calls that are part of a transaction that occurs over many domains. Thus, the first, easiest thing to do is make sure that our frontend tests and backend services support correlation IDs.
A more custom solution is to implement special tag properties within log entries made by client side tests and backend behavior. For example, we could implement the tags, client_ip_address and server_ip_adddress for the log entries made by front end tests and also for the API logs. Then, when the API errors out, we can establish a direct, historical connection between client and server. The failures might be coincidental or they might correlate. Such determination requires a good deal of consideration.
Whether you use a correlation ID or a more robust, special data structure to facilitate binding among many test histories, the important thing is to plan ahead to create a technique that combines the historical data together. Test history correlation is going to become a more important aspect of test analysis, particularly as more enterprises create architectures that make extensive use of microservices.
It Takes a Team to Create Meaningful Test History
As you can see, with some planning and a little elbow grease, the physical aspects of creating test history are quite achievable. It’s just a question of having the processes in place to aggregate metrics from one or more test sessions into a meaningful reporting structure. Thus, having your organization weave test history into the fabric of your testing environment should be easy simple? Right?
Wrong.
Just because creating test history is essentially simple, it does not necessarily follow that it’s going to be easy to implement within the enterprise. Think about this: When was the last time you sat in a design meeting in which developers, project managers, product managers, deployment engineers and testing engineers were present? Me? Up until a few years ago, it never happened. Usually test engineers were assigned to the QA Department downstream in the release process. If they got to see any code before the typical, “release to QA” phase, they were lucky.
Granted things are beginning to change. In an enlightened organization the SDET is an full member of the devone who enjoys the continuous presence in the Software Development Lifecycle granted to all other members. At the least, this means operationally that the SDET is part of the code review process that accompanies a pull request. Also, it means that the SDET’s code is subject to the code review by the team.
According to Martin Leon, an SDET at Apple Inc.,
“Probably the easiest, best way for any company to ensure a testing process that works is to make sure the SDETs are brought in as the product is being designed. SDETs needs to be equal members of the development team, from beginning to end.”
SDET’s are very good at keeping code testable. And, they are very good at helping to determine test metrics that have historic value as well as devising ways to ensure that those metrics are gathered easily and analyzed in a meaningful manner. But, they need to be involved early on. As we have learned on the terrain, if you want the capability to publish useful test histories, it’s better to have test engineering involved from the start of a project. Otherwise, as has been proven time and time again, those who do not know history are doomed to repeat it.
Putting It All Together
Having the ability to generate meaningful test histories is an capability that is not going to diminish. Modern applications are becoming more granular, more ephemeral and much more loosely coupled. Relying on the results of a single test session just won’t do. We need data that is historical. And, we need to be able to bind disparate histories together into meaningful information that describes the software in its entirety. Such capabilities are achievable. The technology exists. The question is do we have the will to make historical software testing happen? Maybe you’ll find the answer the next time you find yourself writing single session test and hear a voice in the back of your head echoing the phrase, “a testing process without history, ain’t.”




