
Disclaimer: There are many different opinions about what technologies are and aren’t considered ML. In this blog post, we consider creating a model of a web application and comparing results of successive tests against it as ML.
One of the most frequently asked questions we get in calls, demos, and through Intercom is “where’s the ML?” As our main page proclaims, mabl is “Advancing QA using ML”, but what constitutes that “ML” and how is it advancing QA? In this article, we’re going to go into the specifics about what tools mabl uses for its machine learning pipeline, how it uses them, and why ML benefits the QA process.
The tools
mabl’s ML pipeline is powered by a trio of Google Cloud tools, as mabl is hosted on Google Cloud Platform. mabl trains visual and run time models of applications using Cloud ML Engine, uses Dataflow to handle the processing of the test data, and uses Lighthouse to track the app’s performance metrics.
Why does mabl use ML?
When we were deciding on what technologies mabl would use, we picked machine learning as the best way to give you consistent feedback on your app as we knew your app would constantly be evolving. This means your tests would naturally have to evolve along with it. The reason the types of feedback listed in the "What does mabl use ML for?" section would be difficult without ML is due to the testing ideas of variability and quality. These ideas include:
Domain variability:
-
One app’s anomaly is another’s normal, so each application has to have a separate model created for it to make sure the anomalies you recieve are accurate.
Temporal variability:
-
Today’s anomaly is tomorrow’s normal, meaning that model has to be continually updated by successive test runs.
Use case variability:
-
Your testing needs may be different from other mabl users, so these models have to be able to adapt to whatever kind of site you’re testing.
Detection quality:
-
Figuring out which anomalies are actually bad (or if they’re important enough to notify you about) so the detection ranges for anomalies mabl uses have to continually shift to encompass any general increases or decreases in site performance and any general changes in your site’s visual design.
Initial quality:
-
Detecting as much about your site as we can with minimal application-specific data, meaning the initial test runs have to give mabl enough of an idea of your site to start comparing visual changes.
How does mabl use ML?
The way mabl finds errors and bugs with your application is by creating a model and then comparing the results of test runs against that model. Specifically, mabl looks at your domain’s variability and creates a measure of detection quality to see if the results your test runs are showing are worth notifying you about (if they exceed the current normal range) or if everything is running smoothly. With a model of your app, mabl has a continually updating and strengthening comparison it can use for test runs. The incremental learning mabl applies to this model from consecutive test runs helps solve the problems of temporal variability and initial quality. By rejecting or accepting the insights mabl provides to you, you are improving that model’s use case variability and detection quality, both through immediate effects on detection and long-term alterations to the model’s training data.
What does mabl use ML for?
Page load performance
mabl looks at each instance of each test’s run time and automatically creates a model of that test’s run time, updating it as the test runs again and again, and notifies you if the test suddenly takes longer or shorter than the model’s prediction range.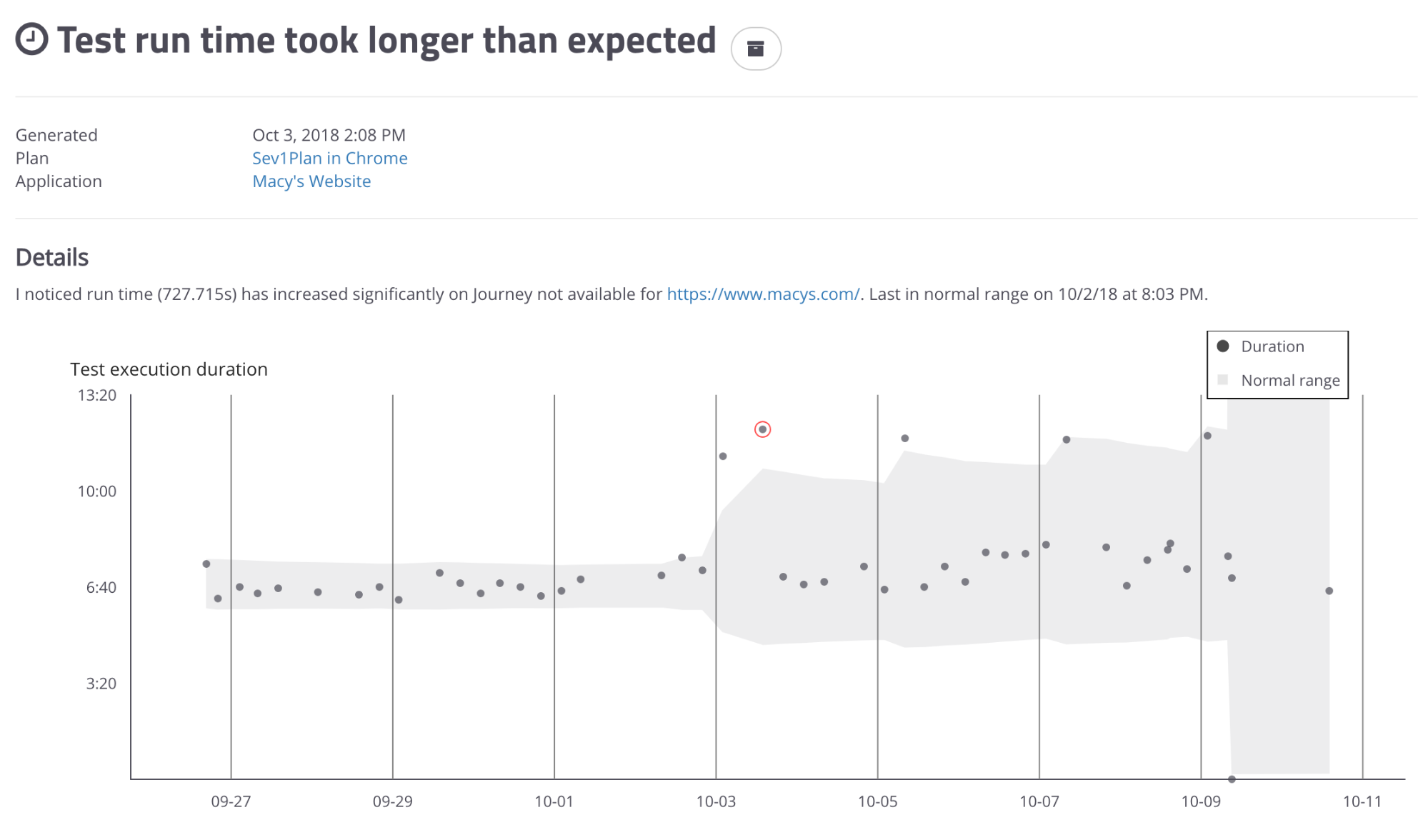
In page load anomaly insights, the gray area represents the predicted range of “normal” behavior and the run times that fall above that area are marked with a red circle around them and reported to you as instances of the test run taking longer than expected.
Visual change detection
mabl creates a visual model of each page visited in the test using the screenshots gathered from the initial runs of the test, with “initial” potentially ranging from the first ten runs to a much higher amount of runs depending on how visually dynamic the site is. By comparing the screenshots, mabl learns to exclude elements that changed during this training period by listing them as dynamic regions. Dynamic regions are areas of your app that are expected to change frequently. For example, a weather map is dynamic since it's changing frequently while a map of your store's location is not since you expect it to change very rarely. mabl ignores dynamic changes when deciding to notify you about a visual change since they’re frequent on many web applications and can lead to false positives and noisy notifications. When changes outside these regions are found, mabl sends the user an insight notifying them of a visual change and highlights the section of the screenshot that changed between test runs.
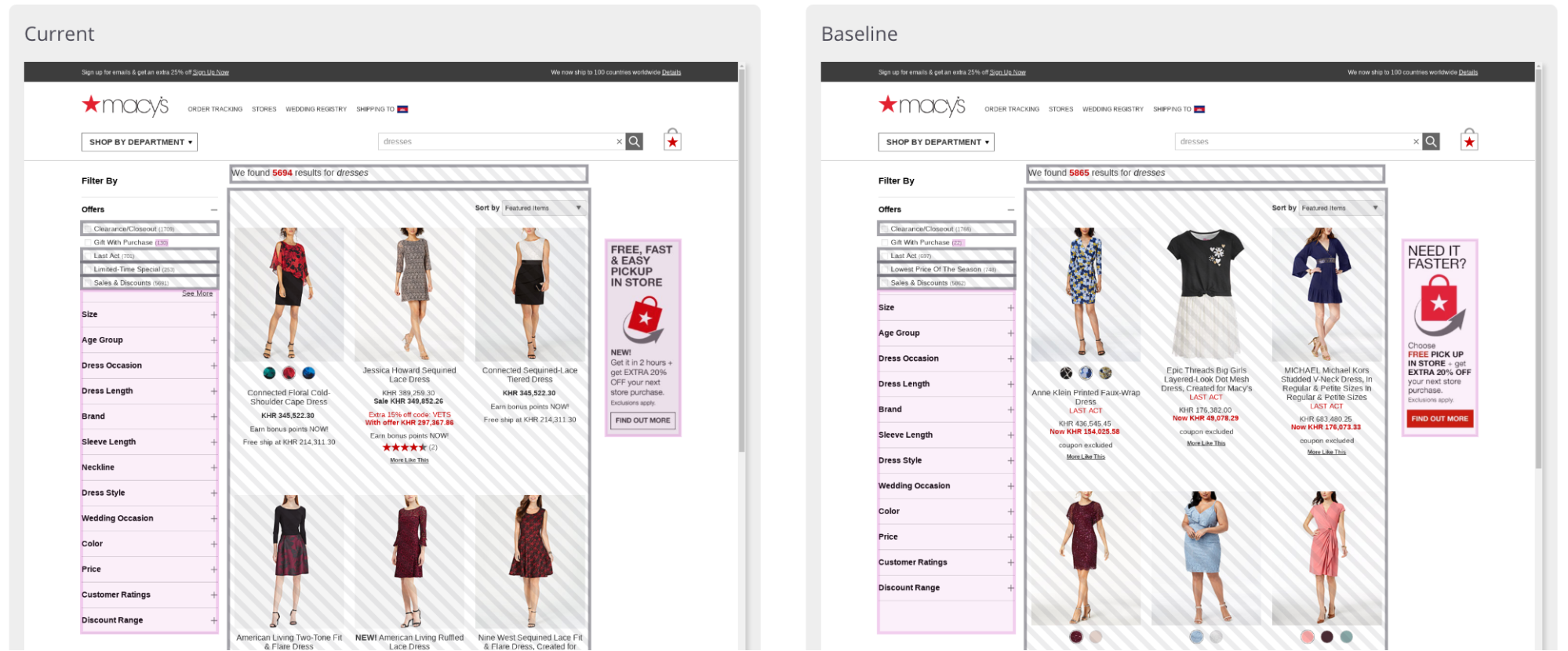
In visual change insights, the areas marked as visual changes are highlighted in purple and the dynamic regions are marked with black stripes.
How does mabl inform you of these anomalies?
The way mabl communicates any bugs or significant changes in the performance of your application to you is through a section in the app called Insights. These are aimed at giving you an understanding of your application’s overall user experience, saving you time by finding bugs for you, increasing your test coverage by giving each test multiple insights it can report, and reducing human error by automating the detection. They appear in the Insights section whenever a test you run encounters a problem (or, if the test passes without problems, you get a nice green check mark insight).
The ML analysis pipeline
Getting these insights from the raw test results requires a concise and focused pipeline on mabl’s part. First, it takes in the raw data and events of your tests and uses them to build the application’s model. Second, it takes the calculated results of your test runs (like their run time) as specific measurements to compare to those observations. Third, it aggregates those measurements and detects any changes between them and the state of your application’s model. Finally, it sends you these detections as insights for you to review.
The truth about ML
When our team decided to build an intelligent test automation service, we knew ML would be a huge benefit to have as it would help us take advantage of the tons of application data we'd be receiving. There are many other areas where we think ML technologies can (and will) be used beyond visual and performance monitoring, such as tracking test coverage and analytics around real user traffic and behavior.
At mabl, we’re asking “How can ML make testing better?” Try mabl for free and see the ML in action.




