
Get a Free Trial
Creating, executing, and maintaining reliable tests has never been easier.
In a DevOps environment, testing isn’t only done once a unit of software is released. Ideally, it’s a continuous process until the software you’re working on has sunsetted. This is because software is immensely complicated. No amount of testing, no matter how thorough or how automated, will completely eliminate bugs from production software. Not to mention, modern SaaS applications are increasingly dependent on integrated third-party services. Testing in production helps you ensure your users are experiencing what you intended. What’s more, users are constantly figuring out new ways to use (and misuse) your application---there’s no accounting for the errors that can occur as these behaviors change.
Research from computer scientist Steve McConnell suggests that software developers ship 15 - 50 errors per lines of code. Any bug that a customer experiences is a chance for a customer to develop a negative impression of your product--which means that testing in production is a crucial firewall against a bad reputation. The only questions that remain are surrounding best practices—what’s most important to test in a production environment, why should you test it, and how often?
Setting the stage for a clean deployment
In order to have the fewest possible bugs during production, mature organizations test early and often. In our infographic blog series, we’ve discussed how organizations can test during the code phase and during the pull request stage. We’ve also discussed the fact that organizations with average maturity tend to begin their testing journey right before they deploy. The best of these moderately mature organizations will set up live QA and production environments that can perform both automated and manual testing at scale.

The difference between QA and staging is that a QA environment can be a bit more ad hoc. Testers can play with configurations, they can use dummy databases, and they’re able to set up more elaborate tests. Meanwhile, a staging environment is much closer to production. Testers perform faster and more limited tests, but the UI is often set up to pull directly from production data. By performing smoke tests on a near-production environment, mature organizations can often eliminate many of the bugs that would otherwise affect customers right away.
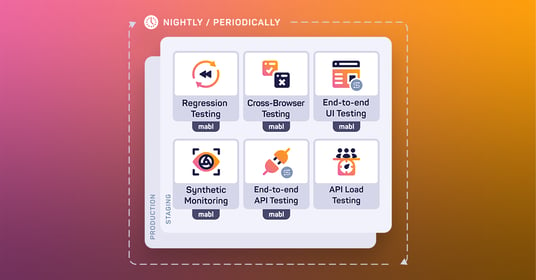
Best practices for testing in a production environment
Testing in production isn’t particularly different from testing in deployment—it’s just that the stakes are higher. Once again, a well-developed DevOps team can deploy up to four times per day. Just as these teams run tests each time they reach the deployment phase, best practice is to run the same suite of tests every time they apply their changes to the production environment. This is because the production environment may contain subtle, yet significant, differences from the staging environment and each one is a chance for a new bug to appear.
In addition, companies may choose to run a selection of tests periodically, as opposed to during every release. Lengthier and more resource-intensive tests have the potential to slow down the application itself—ironically creating the very conditions that testing is supposed to prevent. These tests are usually run nightly instead, where there are fewer users and thus less likelihood of disruption.
The real difference between production testing and deployment testing is the addition of synthetic monitoring. This kind of testing prioritizes testing that mimics the customer’s point of view. Synthetic monitoring runs tests periodically using dummy customer data to simulate journeys through the applications: signing up for newsletters, making accounts, changing passwords, adding items to cart, etc. By running these tests on a continual basis, companies receive instant, near-real-time notifications that tell them whether their application is performing as intended.
One of the advantages of synthetic testing in production is that it accounts for application malfunctions caused by something other than code changes. Modern applications are reliant on API-level integrations usually with a varied stack of third-party software. If any of these third-parties makes a change to the way their software behaves, it will affect your application in turn—breaking either your software or your tests. Running synthetic testing continuously (as opposed to a test suite nightly) gives you early warning when there’s a problem caused by the integrations.
Avoid the cost of production bugs with mabl
Any production bug costs revenue—plus the costs of rolling back a new deployment and keeping your application running while your engineers fix things behind the scenes. With mabl, you can keep production bugs to a minimum—and keep your customers from encountering them whenever possible.
This blog is the fourth and final entry in our series on testing for DevOps pipelines. To learn more, check out our posts on understanding the code stage, pull request testing, and deployment stage testing.
Sign up for a free trial today to see how you can easily create tests that will help you quickly identify and resolve bugs in production before your customers do!




