

Finding regressions in an application is one of the most frustrating time for developers. You’re building a new feature, you have a CI/CD pipeline, and you’re just trying to ship code fast. Unfortunately, the new feature you just shipped broke something that previously worked. Now it’s time to find the needle in the haystack to see what caused the issue, go fix it and make sure this fix doesn’t break the new feature you just built. To accomplish that, you need regression testing, which can be a painful process.
That being said, regression testing is a very important step, especially in modern developer workflows where changes are being pushed several times a day. What matters most in software development is if customers can use your product successfully. We call this the end-to-end customer journey at mabl. Regression testing insures developers are continuing to ship features while not impacting the end to end user journey negatively.
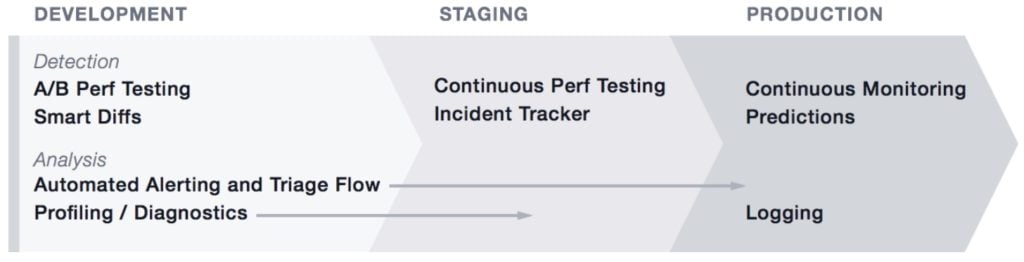
How Can Regression Testing Be Improved?
Part of this user journey revolves around performance, because even if a feature works, if it causes performance regressions, that’s a problem. While poor performance impacts the users of any company, Facebook stands out as the most clearly definable example where small mistakes can add up. They have 2 billion monthly active users (MAU’s), so even a slight or brief performance regression can have a massive impact. In 2013, Facebook embarked on a project to link code changes to regression testing of performance. They call this system CT-Scan.
CT-Scan focuses on two components:
- Pattern detection – capturing metrics, performing statistical analysis, and using machine learning to predict what the performance outcome of a code change will be
- Diagnostics – when there is a regression, gathering enough details to provide to engineers to help understand the root cause of the regression
The Facebook CT-Scan system
As described in Facebook’s blog, CT-Scan is specifically designed to detect and help remediate performance regressions. However, there are several design principles that Facebook uses for CT-Scan which can be applicable to general regression testing. We’ll highlight some of those below.
Regression tests in all environments
Often times, it’s hard to design QA or Staging environments that are similar enough to prod to detect all the issues that could crop up with code changes, especially as it relates to performance characteristics. One of the design architectures that Facebook chose is running regression tests in all stages, including Production. Production regressions are less desirable for them since they require data collection from user devices, but what's a disadvantage for Facebook may not be an issue for many developers that don’t need to collect end user data. One way mabl has adopted this design approach is with the ability to easily repurpose or extend test plans across any and all environments and continuously run these tests. By designing test plans with easy portability, dev and ops teams can work off the same predictions, or expected test results from regression analysis. For example, their developers can run a series of regression tests on pages loading, check the ability to login, or create a complete end to end test in a QA environment. Ops teams can run those same tests in production. The length of time these tests take should be the same across both environments. Both teams can easily work off the same tests and measure the results in exactly the same format, just as Facebook has done with CT-Scan. Ultimately, this portability insures that the performance you experience in pre-prod matches what the user actually experiences in production.
Regressions aren’t only about features
The reason why Facebook developed CT-Scan is because regressions can impact performance, not just functionality. For example, take a customer journey of posting a picture on Facebook. Imagine it takes you 15 seconds to upload a photo, add a comment, and tag a friend in it. Now imagine after a code push, a regression test runs and the test succeeds. However, a second look at the performance details show that it took 45 seconds - 3 times longer for that same journey. This performance, not just functionality, insight is why CT-Scan is so important. mabl has adopted a similar approach. Just as Facebook does, we build specific machine learning models for each of your journeys to predict the expected time range for future test runs of that journey. If any test runtime doesn’t fall into the expected range, we alert the dev, just as CT-Scan would. Below is an example of a test run which took significantly longer than the expected range based on previous runs.
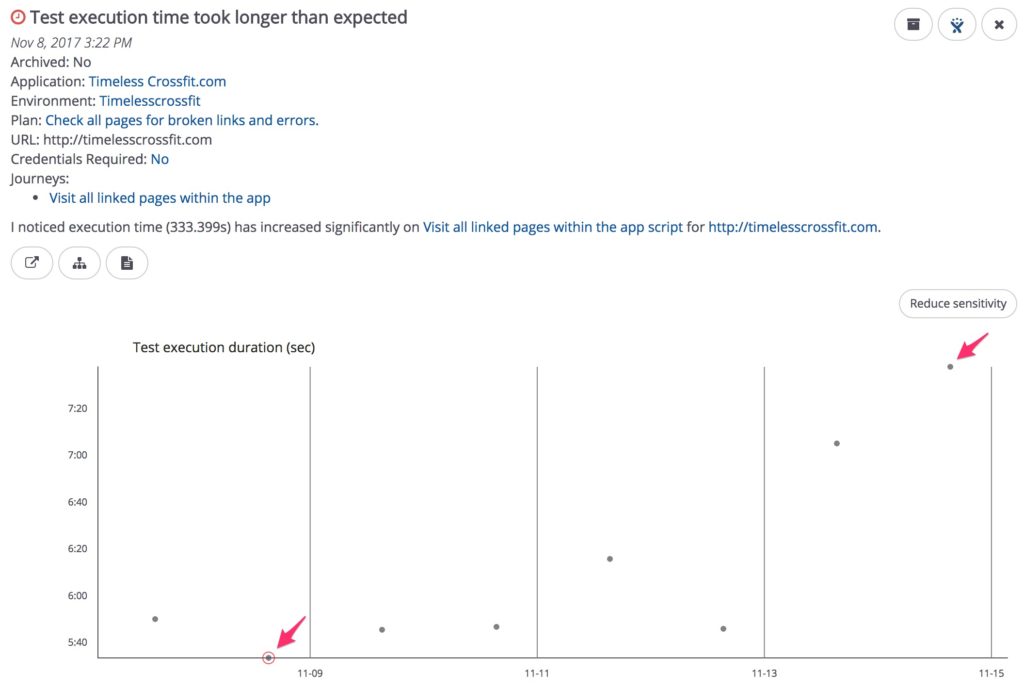
Test execution performance outside of expected range
Regressions are easier to diagnose with data
In addition to actually detecting regressions with CT-Scan, Facebook also collects as much data as possible to help diagnose what’s causing the regressions so developers have what they need to fix the issues. An example scenario they point out is a memory increase after a certain code change. Linking that back to a certain object type in a certain call stack gives the engineer the data they need to diagnose and fix the memory increase. Collecting and using several different diagnostic metrics to help with dev bug resolution is another approach we’ve adopted with mabl. One mabl example is her ability to automatically detect visual changes to your regressions accompanied by screenshots of where they are happening within a test run. In most development cycles, these types of diagnostics are collected and traced back to regressions by humans after the build release. However, collecting this type of data inline with tests allows mabl to automate the correlation as well as increases the pace of the resolution.
Wrapping up
Regression testing isn’t the only type of test we can apply machine learning to. There’s a lot more we can automate, and we at mabl are using ML to make developers lives easier.




