

A comparison between Elasticsearch and Solr, the two most popular open source search engines
In the cloud era, many software applications now generate hundreds of terabytes or even petabytes of data—while continually increasing demand for higher performance. As mountains of data continue to accumulate, it becomes more challenging to perform efficient searches. There are two prominent open source search engines available to address this challenge: Elasticsearch and Solr. Each is built upon the Apache Lucene platform, which itself is also available as open source software.

Though many core features are similar in each of these search engines, there are many significant differences—especially in regard to scalability, searches, and deployment. Based on Google trends, Elasticsearch appears to enjoy considerably more popularity than Solr. But Solr is by no means out of the game, since it also continues on with steady product releases, enjoys a sizable worldwide community, and open source publisher support.
Setup and Deployment
Elasticsearch is fairly easy to setup, and it also has a considerably smaller footprint than Solr. As reference, version 5.5 of Elastisearch is only 32MB while the most recent version of Solr is 140 MB. In addition, for a basic configuration, you can install and run Elasticsearch within a few minutes while Solr takes much longer to install. One of the reasons Solr typically takes longer is that its highly configurable, so if you want better tuning options, Solr gives that to you.
Depending on your type of configuration, you may lean more towards Elasticsearch vs. Solr. If you’re running JSON apps, Elasticsearch may be a better option since it has a JSON-based config while Solr allows you to more easily modify and write comments in the config files, allowing for more fine grained control.
Scalability and Distribution
Search engines must have the ability to integrate with large applications and manage huge collections that might contain millions or tens of millions of documents. Naturally, a search engine should be modular, scale well, and have facilities for replication—to permit easy clustering and accommodate a distributed architecture.
Suitability for the Cloud
One area that Elasticsearch and Solr differ is in how they (or you) manage them in large clustered environments. When running Solr in a clustered architecture, it has an optional distributed SolrCloud deployment configuration that is similar to Elasticsearch, but is dependent on an entirely separate application—Apache ZooKeeper. SolrCloud can provide a high-availability, fault-tolerant environments that distribute indexed content and manage queries across an array of servers. Solr adds complexity by requiring the ZooKeeper app, but it is more adept in avoiding inconsistencies that often arise from the split-brain issue that is common in Elasticsearch clusters.
Elasticsearch takes a different approach, by including a built-in feature called Zen, that directly manages cluster states. This built in capability makes Elasticsearch easier to start in a clustered environment vs. Solr, as long as inconsistencies are kept in check by the user.
Shard Splitting and Rebalancing
Apache Lucene forms the core of both Elasticsearch and Solr, and it employs shards as the partitioning unit for any index. An index is distributable by configuring shards to run on separate machines within a cluster. Sharding is one way to scale your search application. Though Solr previously lacked the ability to change the number of shards for an index, SolrCloud now supports shard splitting—by which you can split one or more existing shards in an index. Sharding is the key to how Solr search scales as requirements increase.
Elasticsearch approaches this design problem from a different angle. They encourage accurate capacity planning, where you estimate future growth and expand your Elasticsearch cluster ahead of demand. Add more machines to your setup and then use the Elasticsearch shard-balancing feature. The bonus is that this will obviate the need for shard-splitting. With thoughtful planning, ElasticSearch can automatically rebalance the load as necessary, and move shards to other cluster nodes. By default, Elasticsearch sets five shards per index. The number of primary shards isn’t configurable, but you can increase the number of replicas. When adding a new machine, Elasticsearch will rebalance the available shards in each of the machines. This feature is useful for horizontal scaling as your search application grows.
Indexing and Searching
Searches
The content that you’re searching for should be a key consideration when deciding between Elasticsearch and Solr. The primary strength of Solr is in text search while Elasticsearch is very strong in analytics queries, grouping, and filtering. Let’s say that we want to search for future entries containing “Jack” that might appear in a particular dataset. A simple full-text search for Solr might look something like this:
Solr
…/collection1/select
?q=jack
&fq=when:[NOW TO *]
&rows=1
The same query in Elasticsearch is more elaborate, and is likely to be slower.
Elasticsearch
GET /test1/hello/_search
{
“size” : 1,
“query”: {
“filtered”: {
“query”: {
“query_string”: {
“query”: “jack”
}},
“filter”: {
“range”: {
“when”: {
“gte”: “now”
}}}}}}
Moreover, as Ryan Sonnek is keen to insist, Solr is fast. Very fast. Out of the box, it’s quite stable and reliable—and outperforms virtually all other search solutions for simple full-text searches (this includes Elasticsearch).
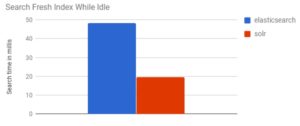
But, it’s really quite easy to bog Solr down. If you need to perform search while simultaneously updating the index with more content, you will frequently encounter serious performance problems—especially if it’s necessary to make regular updates to your search index.
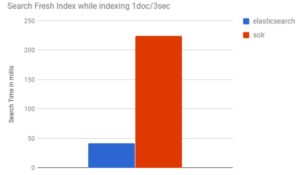
If you want to pile several million documents onto the index, you will absolutely crush Solr but Elasticsearch will take it all in stride.
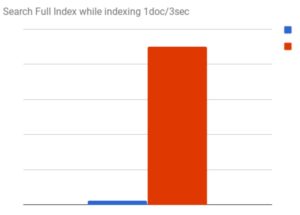
Solr simply wasn’t built for real-time search. The persistent, intensive demands of most real-time web applications require near-instant delivery of updates as users continue to generate new content. The distributed architecture of Elasticsearch gives it the power and flexibility to easily handle high-volume index updates simultaneously with a high number of real-time search requests—without any performance degradation.
Without question, Elasticsearch is the best choice for those applications that require the ability to perform complex, time-series searches and aggregations.
Both Elasticsearch and Solr use analyzers and tokenizers to decompose text into terms (or tokens)—which are then indexed. Elasticsearch provides the option of specifying a query analyzer chain, which consists of a series of analyzers/tokenizers. This is especially efficient when attaching multiple analyzers, since the output of the preceding analyzer feeds into the input of the next analyzer.
Indexing
In either of these search engines, stopwords and synonyms can be used to find matching documents. To run a search in Solr to discover relationships among multiple documents (as in the case of an SQL join), a join index must be done on single shard, and be replicated on all nodes. This can be done as Solr supports hierarchical searches although it’s not as easy as Elasticsearch. This type of search in Elasticsearch however is much easier, only requiring the use of a has_children or top_children query. Not only is it more efficient than Solr, this type of search can find matching parent documents together with its child documents.
Choosing the Best Search Engine
Each of these search engines has different features and strengths, so it’s important to clarify your requirements first. One thing to keep in mind is that Elasticsearch is easier to setup and configure, so it may be a good choice for more junior developers. For more fine grained control and advanced use, you’d want to consider Solr.
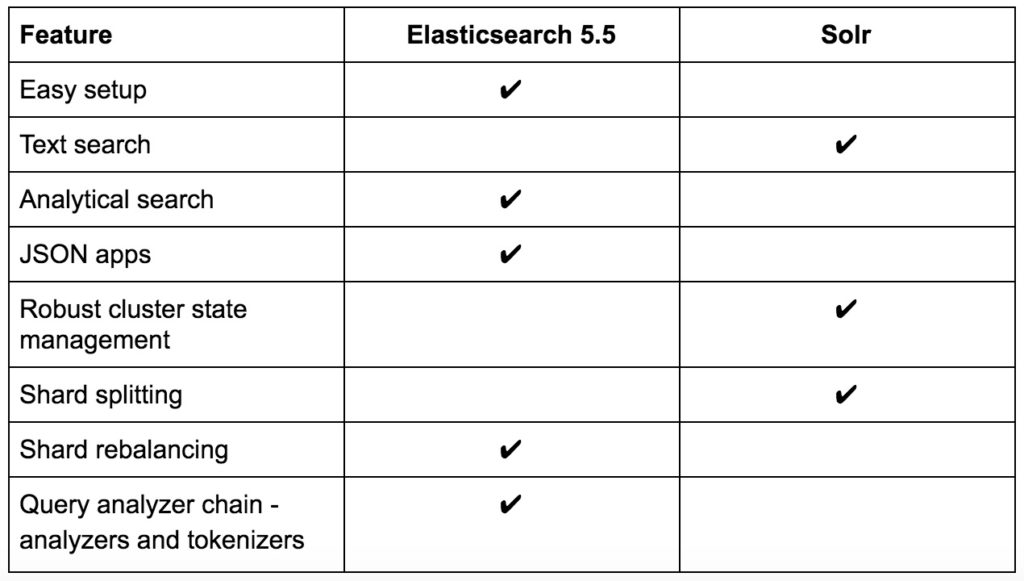
This table is a short-and-quick comparison of the major features of Solr and Elasticsearch. A checkmark indicates which search engine gets our recommendation for that feature.
Sign up to reserve your spot for mabl, the ML-driven end to end testing service as soon as its avaiable.




