

One of the most important types of testing needed in order to maintain software quality and avoid accruing technical debt is regression testing. We'll explain what it is and provide a few guidelines for how to apply it.
At the most basic level, regression testing is simply a form of testing that verifies if any code changes to an application affect other already-implemented features. Regression simply means a “reversion to a previous state. “ As we apply this to software testing, we are verifying that nothing is “regressed” or returned to an “unworking” state as an unintended consequence.
When conducting regression testing, you're making sure that recent code changes did not accidentally reverse positive development and cause parts of the application to no longer function properly.
Why is regression testing important?
Ideally, code revisions or additions should affect only the part of the application under revision or development. In reality, this is often not the case; a change can cause problems at multiple levels. Let’s break down the types of problems that can occur:
Local Regressions
Local regressions occur if a code change to a part of an app causes the feature to malfunction for a different reason unrelated to the code change. For example, say you’re working on a web form. Requirements specify that a few fields need to be required, so you make a quick fix. These fields are now required as specified, but for some reason other fields which were not required suddenly start requiring entries - another undesirable state. This is “local” in that the regression appears in the same part of the app where the code changes were made.
Remote Bugs
Remote regressions describe when a code change to one part of an application causes an error in another part of the app, usually due to common dependencies. Let’s go back to our previous example. Perhaps you decided to make a form field optional. This seems to work fine in initial testing, but it results in null values in the database that cause other features that use this data to work erratically or not at all. These errors could appear in an entirely separate part of the application, causing issues where none existed before.
Unmasked Bugs
Sometimes bugs already exist but are in a sense, dormant. When a new piece of code is deployed, these hidden bugs can suddenly appear.
In some cases, there may be faulty code that never triggers until a code change unearths it. Pre-existing bugs can be difficult to troubleshoot quite simply because the change did not create the bug so there’s nothing in diffs to indicate what went wrong. It simply uncovered a bug that had always been there.
Changes to Environment
Large scale changes to an environment such as a version upgrade of a framework are likely to bring about regressions in many areas across the application. Deprecations are common with version updates; failures may come about when new standards are applied.
Sometimes issues which do not appear in one environment show up when moving to another similar one, such as a move from a development server to production. While it may appear that you’re running identical servers, there can often be subtle differences that are not immediately apparent. For example, the development server may not have as many security provisions as a production server. Discrepancies such as this can cause anomalies and unexpected issues.
Whether upgrades or migrations from one system to another occur, this is a prime situation for running an end-to-end test to identify if anything has been broken in the process.
Types of tests
Unit Testing
Unit tests, which are written to check the behavior of the smallest units of code, will catch most defects and many local regressions. It’s a good idea to build automated unit tests into your deployment process so that you can ensure your code is reliably working as expected through development into production. Unit tests are relatively pain-free being easy to design and write, and should be considered part of the development process.
Integration Testing
When a module of software is designed to integrate with other modules or components (or for that matter, external components through APIs) it’s a good idea to run integration tests to check that interactions between two software components are working properly.
System Testing
System tests are tests that verifies that the behavior of the entire system assembled together is as expected. This encompasses that the functionality of the application is working, but does not necessarily check how the system works once plugged into other external systems.
Acceptance Testing
Acceptance testing is usually when your end-product is plugged into external systems and put in front of real end-users to beta test the product. End-to-end tests are conducted here to verify that the application meets not only functional requirements but business needs and SLAs.
When to do Regression Testing
Regression testing should occur every time any change is made to a system, whether it's a unit test or end-to-end test. End-to-end tests can be expensive, so you may need to limit how you use them. There are important ways to narrow this down without sacrificing effectiveness. The test automation triangle paints a good picture of how your test strategy should, be designed in order to max our your effectiveness, suggesting that you should have the most unit tests, lesser integration tests, even lesser acceptance tests, and the least amount of end-to-end tests.
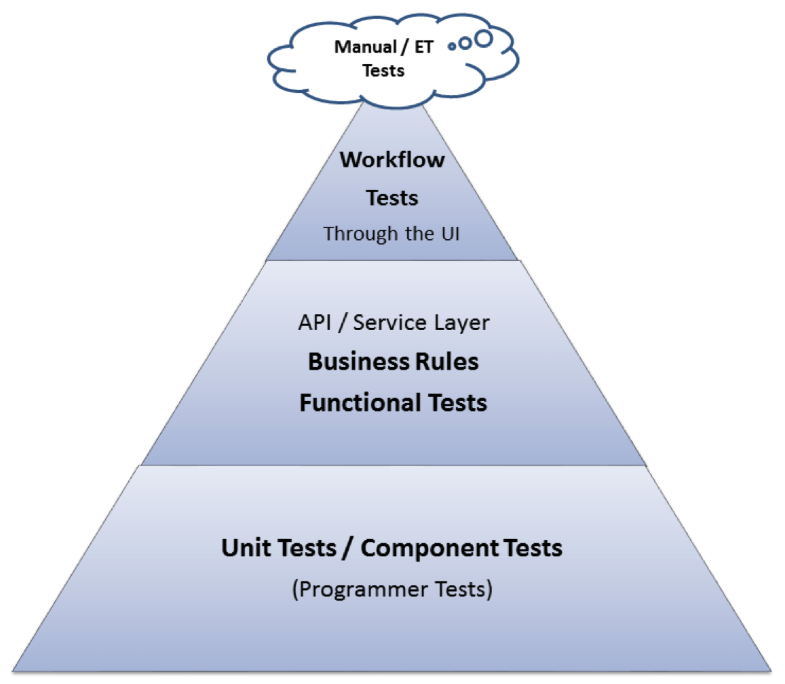
End-to-end tests are the most effective form of regression testing as they should theoretically catch anything wrong with an application, but not particularly efficient, and can be expensive as they're more difficult to design and write and takes up the most computational resources to run. You can think of them like an MRI in a hospital. While they are effective to catch anything that might be wrong with you, you don’t get one done every checkup.
If forced to limit the amount of regression testing you are doing, it’s good to prioritize test cases by business need. Business importance should always be considered. It’s good to occasionally run through core functions periodically to make sure that the system will pass a basic smoke test.
Note: smoke tests do not qualify as true regression tests, as while they’ll catch things that are actually “on fire” and showing impact, they don’t necessarily catch low-level bugs. For this reason, this approach should be used only as a quick and dirty measure but not for acceptance level testing.
Summary/Recommendations
Automation
As may seem clear after reading this article, to do proper regression testing will require some automation in order to do enough regression testing. Without automation, it would be virtually impossible to catch many regressions except as a matter of chance unless one has the resources to deploy a team of 50 humans to regularly run over each and every bit of the software each time a change is made. Using tools such as mabl will make the entire process considerably easier, and you can prepare tests throughout your development process which can be used as a library when do your final end-to-end tests.
Regression Testing With mabl
With mabl, you can quickly detect bugs and get deeper insights via AI-driven automatic regression detection. All you have to do is run your tests and mabl will give you the comprehensive results you need to troubleshoot and fix bugs quickly.
mabl is able to:
- continuously run end-to-end regression tests after every deployment
- effortlessly integrate into your CI/CD pipeline
- automatically detect Javascript errors, broken links, visual changes, and performance slowdowns
Sign up for a free trial of mabl to supercharge your regression testing today.




