

Seems that there is little doubt these days that serverless computing is all the rage. We’ve moved from the world of applications running on Virtual Machines, through less resource strict Containers, to a place where the function ends up being the deployment unit of the future. Seems as if everybody is jumping on board with the idea. Amazon has AWS Lambda, Microsoft offers Azure Functions and Google is sneaking in with Cloud Functions.
The Premise of Serverless Functions
The premise of all the products is similar. Instead of creating software that is made up as an aggregation of data and behaviors represented as a distinct application which is deployed into a virtual machine or container, with serverless computing all you deploy is a function that resides in a host’s public cloud, not to a particular machine. Then, the function is wired to one or many mechanisms that trigger execution, a response to a call to an URL in AWS’s API Gateway or to a message received on Azure Queue storage, for example.
Great. So, what’s the benefit? Well, if you listen to the powers that be and the marketing departments at AWS, Microsoft and Google Cloud, you pay only for the executions you use and you don’t need to keep any developers on payroll scaling your infrastructure up or down to optimize your costs. Scaling is built into the products.
Again, great. But it’s not really a new idea. We’ve been here before. For those of us old enough to remember, calling a single function in another process outside of a client computing environment is called a remote procedure call (RPC). The concept and the technology to execute the concept has been around in commercial use since 1981 when Xerox released Courier and later made a bit more mainstream in 1984 under Sun RPC. But, that was then and this now. Serverless computing is the current bright, shiny, object and will be with us until something else comes along. Why? Mostly I think because AWS released Lambda Functions which caught on and Microsoft needs to have an analogous technology to keep and grow it’s market share? Why is Google jumping into the fray? Dunno. Maybe because it can?
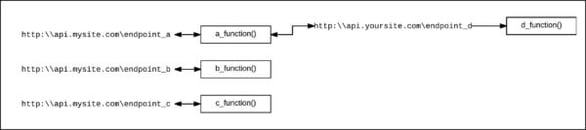
So how does this play out for those developers that have to make products in the real world? It seems that the future architecture of applications will be a client/serverless model in which the client will be a phone, tablet or desktop computer native application or browser page wired under HTTP and its cousins (think: XMPP or AMQP), to an API in which each endpoint is bound to a serverless function. Those functions might indeed execute other serverless functions by way of calls to endpoints accessed internally within the given function, (See Figure 1, below.) which is all well and good except when it comes to testing.
Testing, or Lack Thereof, in the Age of Serverless Computing
I am a proponent of Test Driven Development. I used to be extreme about it. Now I am pragmatic. When it comes to coding for cash, I like to prove that all the code I’ve written has been exercised and that the code works as expected. Thus, two reports are essential to me: Test Pass/Fail and Code Coverage. I want all my tests – Happy Path and Unhappy Path – to pass and I want to make sure that these tests cover at least 90% of the codebase, if not 100%. This is at the developer level.
At the systems level, meeting performance standards as well as not blowing up machines by eating memory, pegging CPUs and gobbling disk space needs to be ensured via repeatable testing mechanisms.
Now, all of the tests described above are possible when you “own the box” albeit real or virtual. But when the box goes away, e.g., serverless computing, you are in real trouble, for a variety of reasons. Your testing process becomes fragmented and disparate. Unit testing and code coverage can be ensured to be consistent between developer machines and the Continuous Integration/Continuous Deployment (CI/CD) check-in process because you can run the same testing tools locally and in the CI/CD environment. Thus, given that your data is consistent, tests passing on the developer machine should pass in CI/CD. No problem.
But, say goodbye to your unit testing and code coverage mechanisms when you start deploying to the serverless environments. Yeah, you can build in test calls as part of the internals of the functions being deployed, but such an approach is a kludgy long-shot. And, there is no way you are going to get code coverage measurement among all the client calls to functions via the given API. Remember the functions do not live on a machine that can also run the code coverage tools: can’t measure what you can’t see. So how do we test? Seems that the way to test is to go to integration testing, system and performance testing while taking a Behavior Driven Development (BDD) approach.
Many of us have come to understand that a key element of testing is environmental consistency, that each testing environment should be identical to the next: same OS, same memory configuration, same libraries to the version level, etc…. Even the same physical hardware, if possible. But, when it comes to testing in the serverless computing environment, after having somehow figured out how reliably and repeatedly deploy the hundreds of functions you’ve written and tested in Development, how do we really know that our QA environment is identical to our Staging environment which is, in turn, identical to our Production environment? Having some operational familiarity with AWS Lambda functions, I can tell you that all you really know is ... your account ID.
So you put your hundred or so functions up there and hope for the best. And then something goes wrong, say an unexpected memory consumption in production. Now what? All you have are the application logs and maybe, just maybe some system logs. There is no debugging in your serverless Staging environment. (Yes, I know, nobody debugs directly in Production, but remote debugging against Staging is not unheard of.) And, all you have is your host provider’s word that the environments are consistent, if not identical. But, still you have the problem and you are back to the 1980s approach to debugging: looking at the logs, which at that point you start kicking yourself because your team never really discussed logging policy and came up with a way to ensure that the information you will most probably need in the event of disaster is available.
Of course, as is typical, things started going south on Friday before lunch. Hence, you call your significant other and opt out of weekend plans. Then you hope your company bought a reasonable support plan from the provider so that you don’t have to go it alone solving the problem. Such is life in the world of serverless computing.
Another Bright, Shiny Thing?
Technological innovation is a pendulum swinging between two points, centralized computing and decentralized computing. When the mainframe came out the pendulum went to toward the centralized end of the spectrum. The advent of the PC sent it the other way toward the decentralized end. The Internet and the emergence of the cloud seems to be sending the pendulum back toward centralization – millions of users connected to the motherships of all the Facebooks, Spotify and Snapchat’s in the world.
However, each swing of the pendulum is not the same. Every time the pendulum goes back and forth, there is something a bit new about the swing. Are we moving in the direction in which there will be three central cloud providers, AWS, Azure and Google Cloud? Seems that way. But when you look under the covers, there is not one master machine for each provider, rather billions and billions of nodes of commodity hardware living in hundreds of data-centers. So, in a way this is a new type of trip on the pendulum’s journey toward centralization.
Is serverless functions going to be a bright, shiny, object on the landscape of cutting edge cloud computing? Dunno. There are a lot of time and resources being devoted to the technology by all the parties involved. So the odds of success are good. However, in order to make serverless computing real world, processes and products need to be developed that allow companies to consistently and reliably test the software destined for the serverless environments. For now, Behavior Driven Testing methods that monitor and archive test results coupled with rigorous logging policies that keep track of internal behaviors will do, but not for long. The volume of activity anticipated on the horizon of serverless computing demands better automation tools and automated techniques, particularly around deployment and testing. Otherwise, we run the risk of serverless computing being cool only because the providers say it is. And as we have learned on the terrain, a bright, shiny object is only as interesting as the others that have yet to appear. If you have other ideas on how you’d test in serverless environments, I’d love to hear them!



