

In today’s continuous world, many teams strive to deploy small changes to production frequently, often on a daily basis or multiple times per day. To build confidence for continuous delivery or deployment, teams need the fastest feedback loops possible. They need test results within minutes of each new commit to the source code repository. Being able to quickly respond to production issues by getting fixes deployed rapidly is also key. Running automated regression test suites is an essential part of that deployment pipeline. The tests need to run quickly and reliably.
When to consider running tests in parallel
Breaking up a test suite and running different sections of it concurrently, whether on different machines or virtual machines, is a tried and true practice. It’s a good practice in most contexts to keep your end-to-end workflow tests to a minimum. Still, any test running at the UI level through a browser is going to execute more slowly than lower-level tests. Running them in parallel is an obvious way to speed up your CI pipeline.
Today’s cloud infrastructure makes it possible to run each test in its own container. Some test tools, mabl included, offer this capability, which enables even large numbers of tests concurrently. When your feedback comes as quickly as the time your longest individual test takes to run, your team’s deployment pipelines can finish much faster! Teams need this speed so that they can quickly resolve a production issue by reverting or fixing a change.
Potential pitfalls
Teams who start running multiple automated tests concurrently often run into trouble, even when running each test in its own container in the cloud. This can be avoided by having each container also have its own self-contained test environment and test data. If all the parallel tracks share one test environment, including the database, tests can create conflicts. For example, if there are two tests that both log in to the application under test with the same account credentials and start making updates, those updates can step on each other. Test A may delete a record that Test B was preparing to update, causing Test B to fail.
Tests can even create deadlock conditions, where more than one test tries to update the same records in the database. Here’s an example: Test 1 has locked a row in the Employee table to do an update and update the Salary table for the employee as part of the same transaction. Test 2 has several rows locked for update in the Salary table, and also needs to update the same row in the Employee table that is locked by Test 1. Each test will wait for the other to give up the lock, and nothing will happen until the database system detects the deadlock and cancels the transaction being done by one of the tests. 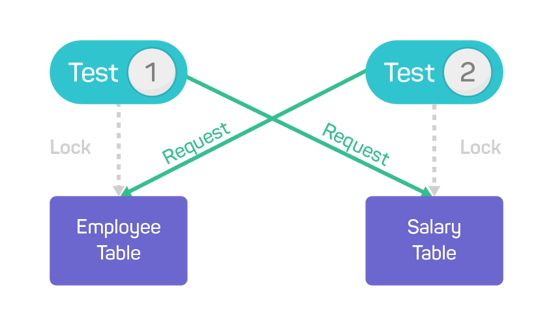
Race conditions are also a danger. Let’s say you have automated regression tests around permission levels for individual users, related to security. Test 1 logs in as User A, who has update permission, and performs an update. Test 2 changes User A’s permission level to read-only. If Test 2 runs at the same time as Test 1, Test 1 may end up with unpredictable behavior or an unexpected runtime error.
 Race conditions can cause cyclical behavior or other unexpected behavior
Race conditions can cause cyclical behavior or other unexpected behavior
Preventing the pitfalls
Good test design practices avoid contention among multiple concurrent automated tests. They’re useful even if you don’t run your tests in parallel!
Keep it simple
Keep each individual test to one clear purpose. Don’t try to verify multiple scenarios in the same test. Simplifying the tests makes it easier to keep them from potentially affecting the results of other tests run at the same time.
Design independent tests
When possible, it’s a good practice for each test to be independent, to set up its own unique test data and state at the start of the test. That eliminates the chance for contention among multiple tests running at the same time. At the end of the test, whether it runs successfully or not, it should clean up after itself and restore the system to the same state where it started. For example, delete any test data that it created, undo any updates, leave the campground as clean as when it started. Otherwise, unexpected behavior could occur the next time the test executes.
Another approach to making sure tests have the correct data and system state to work with each run is to use canonical or fixture data. This is a set of data which is loaded into the test environment, so that the same starting values are present each time the test suite runs. If any data is corrupted by an unsuccessful test, it will be returned to its normal starting state the next time the suite kicks off.
Make sure each test has unique values for variables and data. For example, to test signing up as a new user, generate a random value as part of the username and email address to prevent duplicates. Any test that logs into the application under test should have its own unique user account so that it doesn’t interfere with other tests that log in and make updates.
“Stub out” the parts of the application you aren’t testing
If your tests or the application they’re testing interact with third-party systems or parts of the application they aren’t meant to test, consider using test doubles to replace those objects for testing purposes. For example, having the tests use an in-memory test database instead of a physical database not only helps ensure unique test data, but also speeds up the tests because I/O is reduced. Mocks can be used to test calls to other parts of the system or external applications by verifying the format of the request they receive while not performing any real actions as a result.
Start small
If you aren’t sure whether your existing automated tests have dependencies on each other or on certain test data, start by running just a few tests in parallel. After several iterations of successful test runs, you can feel confident to run more tests concurrently. If you do discover problems, you can address them by refactoring each test to make it independent, breaking it into multiple tests if necessary. You may also need to add to or change your test data so each test can work with a unique set of test values and system state.
Modifying tests to run in parallel, and designing new tests with this in mind, leads to better-designed, more reliable tests. The practices described here are important even when tests are run in sequence. Letting the tests provide faster feedback by running them in parallel in the cloud will give your team more confidence to deploy small changes to your product more frequently.
Not sure how to get started?
If this is a new idea for your team, see if you can get help from your operations specialists. There are many options for building the infrastructure to be able to run automated tests in parallel in your continuous integration pipeline.
If the infrastructure is a challenge right now, consider available tools such as mabl that have the capability to run automated tests in parallel as well as in sequence.
Resources:




