
Get a Free Trial
Creating, executing, and maintaining reliable tests has never been easier.
The Development Phase is the stage in the Software Development Lifecycle (SDLC) in which programmers create the code that makes up the software. In addition to creating application source code, the Development Phase includes activities such as database development and environment orchestration. After all, in a world in which infrastructure is code, creating a computing environment via code involves much of the same thinking as any other aspect of software development.

The rule of thumb when testing in the Development Phase is the person writing the code, tests the code. And, any test written must be able to run repeatedly in an automated testing environment well after the code moves away from the developer.
Unit testing is the place to start when implementing testing in the Development Phase of the CI/CD pipeline.
Unit testing is the process of testing discrete functions at the source code level. A developer will write a test that exercises a function. As the function is exercised, the test makes assertions against the results that the function returns. Functions that do not return a result are not good subjects for unit tests. Such functions alter the state of the system beyond the scope of the given function. Thus, the function needs to be tested at the integration or system level. Unit testing is about exercising discrete functions, that are well encapsulated and return a result upon execution.
The notion of testing a discrete function might seem simple and obvious. However, it’s sad to say there is a lot of code out there that puts too much application logic into a single function. Instead of covering a single area of concern, the function is all over the place. This is called spaghetti code. (See Figure 1). Spaghetti code is hard to unit test.
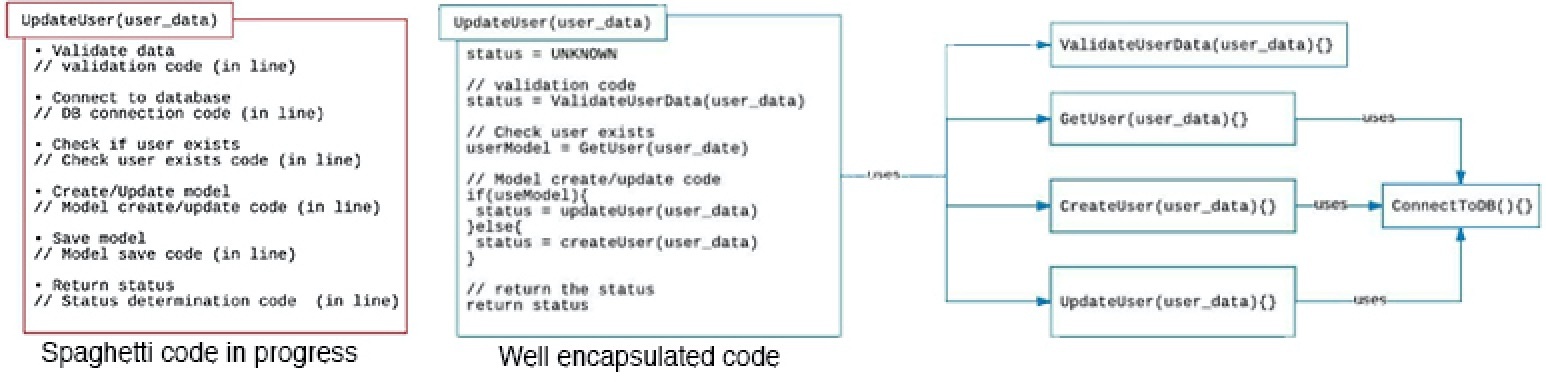
Unit testing is most reliable when exercising well encapsulated code
Unit tests are most effective when exercising code that has discrete functions in which each function has a single area of concern. A discrete function delegates behavior outside of the function’s area of concern to another function. For example, as shown in Figure 1 previously, the well encapsulated function UpdateUser(user_data) uses the function, ValidateUserData(user_data) to determine the validity of user data passed to it. User validation does not happen in line within UpdateUser(user_data). Thus, when it comes time to write a unit test for validation, that test needs to be written against the function, ValidateUserTest(user_data), not against UpdateUser(user_data). Unit testing against well encapsulated code is cleaner and easier to control. When something does go wrong, bad behavior will be confined to an easily identifiable function.
Tools of Unit Testing
Examples of the common tools used for unit testing are JUnit for testing Java code, NUnit and MSTest for testing .NET code, Mocha/Chai for testing NodeJs programs, unittest for testing Python code and PhpUnit for writing unit tests for PHP. C++ is language that has been around for along time and has a broad implementation base. Thus, there are many unit testing frameworks to choose from when unit testing C++. You can view a listing of C++ unit testing framework here.
Pass/Fail and Code Coverage: The 2 Basic Metrics for Unit Testing
Committing to writing unit tests is an essential first step in the process of testing in the CI/CD pipeline. However, commitment is more than writing tests. The tests that are written must be reliable. In order for a test to be reliable the results of the tests must be measurable. The two metrics for unit testing typically used are 100% Pass and Code Coverage.
Understanding the 100% Pass Metric
The 100% Pass test metric is exactly as the name implies. A unit test is executed. Either it passes or it fails. All unit tests running against a code base need to pass. Any test that fails anywhere in the CI/CD pipeline creates a risk that needs to be addressed immediately, particularly if the given test has a history of passing.
Supporting a 100% Pass metric has a direct impact upon the way unit tests are designed. Tests are based on assertion. In fact, in order for a test to be valid, it must contain at least one assertion. However, things get tricky when the number of assertions in tests grows.
Usually a test that has a large amount of assertions runs the risk of becoming spaghetti testing. For example, imagine a test named validateUserDataTest that has ten assertions. Having a large number of assertions means that the test is validating different aspects of the function’s behavior. If any one assertion fails, the entire test fails. But, given the large number of assertions in the test, it’s hard to know exactly which validation is causing failing behavior.
Another approach to unit testing is to segment various assertions into separate tests when reasonable. Some development shops have a policy of one assertion per unit test. Other shops are more flexible. But, just about all shops committed to comprehensive testing in the CI/CD pipeline require that assertions are well segmented and limited to validating only one aspect of a function’s behavior. (Please see Figure 2, below.)

Well segmented assertions make for more reliable testing
Supporting the 100% Pass metric goes a long way to ensuring the development of high quality code. However, 100% Pass alone does not solve the problem. Imagine a code base that has fifty functions. But the developer wrote 100% passing tests that exercised only forty functions. Clearly there is a risk. But, quantitatively how do we know that not all the code that was written was tested. This is where code coverage reporting comes in.
Understanding Code Coverage Reporting
Code Coverage Reporting is the way we know that all lines of code written have been exercised through testing. Most modern unit testing frameworks provide code coverage reporting. Figure 3 below shows the code coverage capabilities of unit testing under Android Studio.
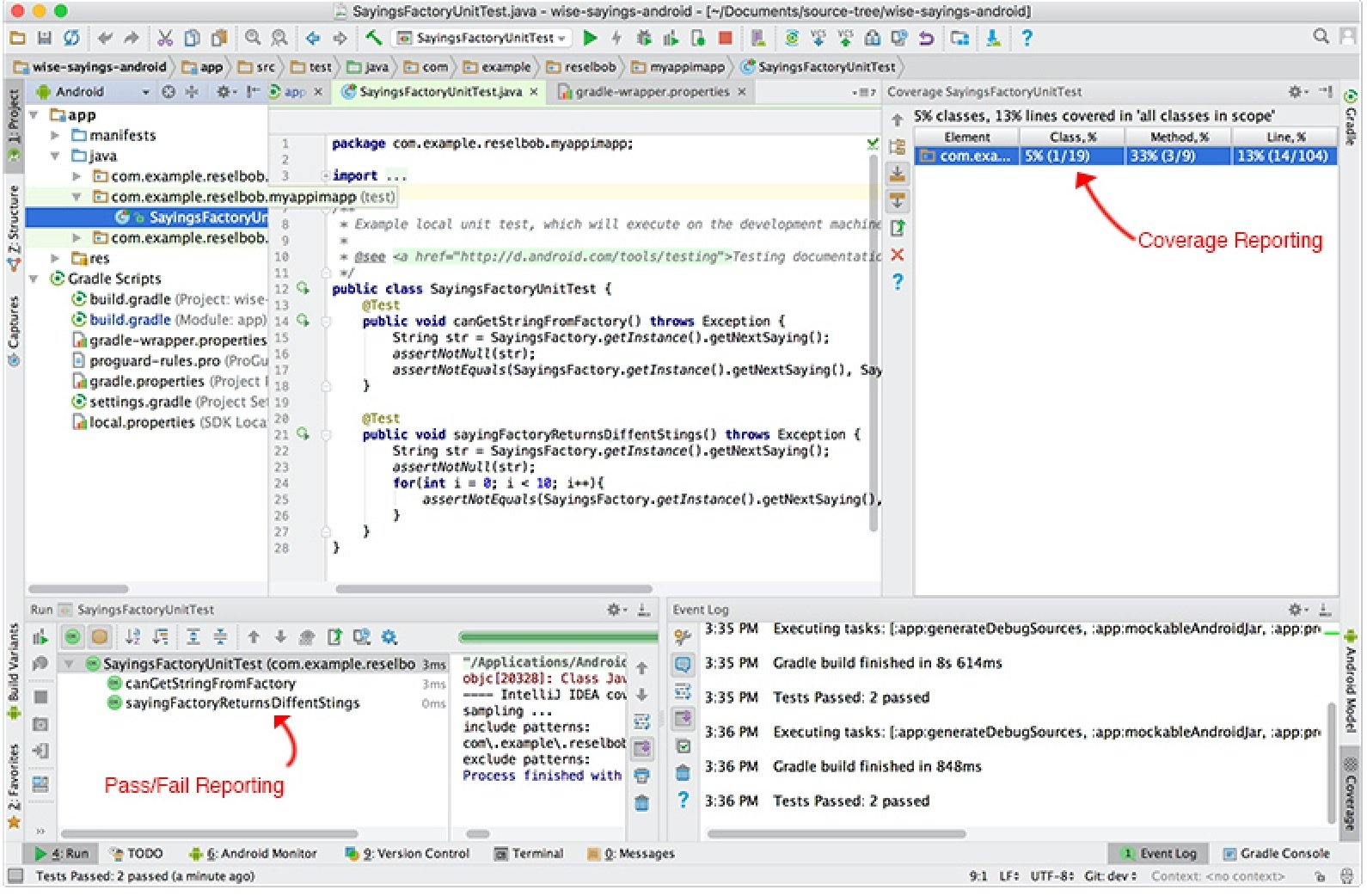
Android Studio provides code coverage reporting as part of its unit testing framework:
Figure 4 below shows a typical code coverage report in HTML format. The lines of code that have been exercised by a unit test are highlighted in green. Lines of code not exercised will be highlighted in red.
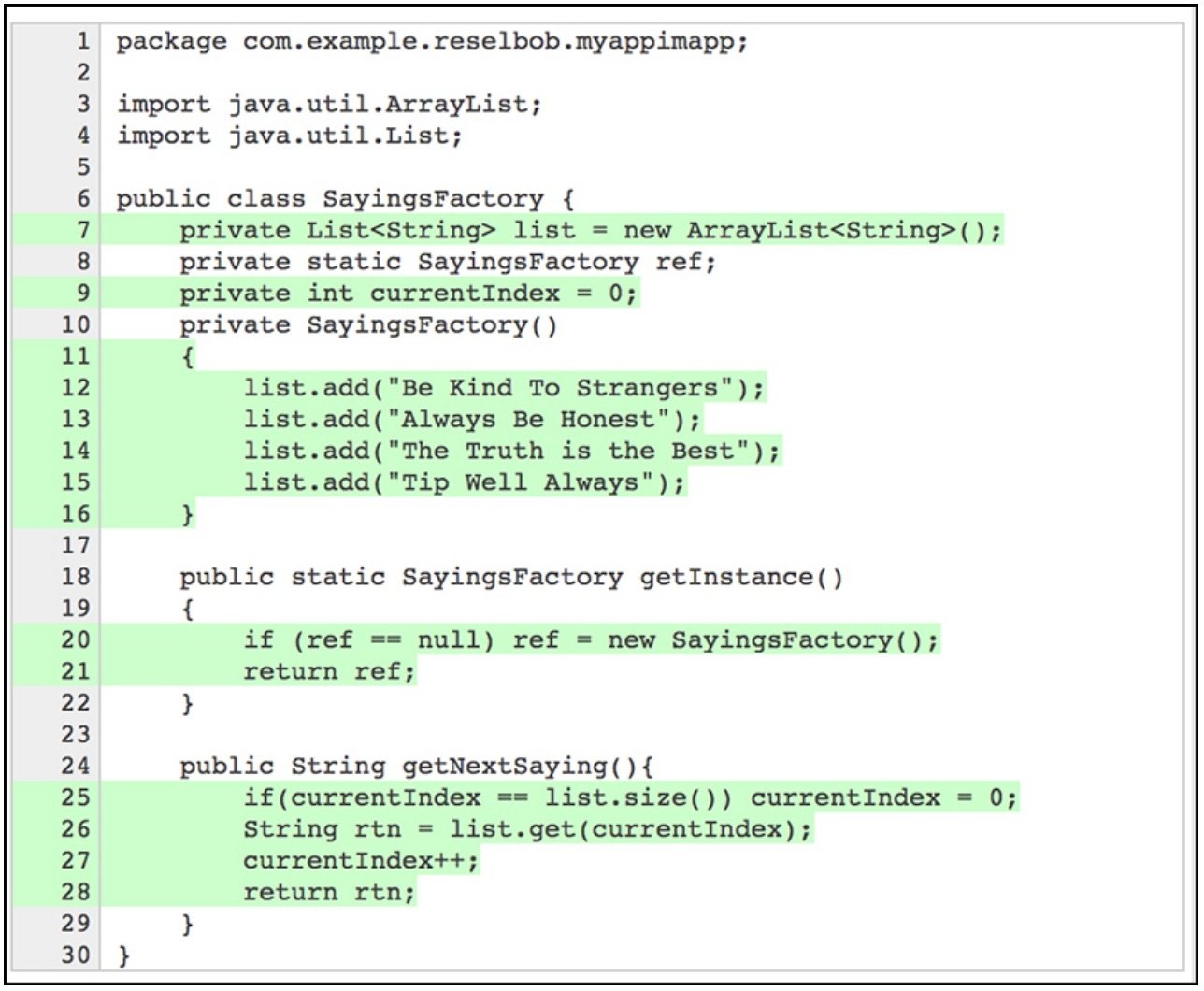
Most code coverage reporting tools will provide a way to visually determine the lines of code exercised by unit tests.
The value of code coverage reports is that they provide an exact way to measure the validity of unit testing. As mentioned above, it is entirely possible to have 100 unit tests passing 100%, but have only a fraction of the code base actually exercised. Code coverage reports provide the information necessary to determine the overall validity of a developer’s unit tests.
The acceptable percentage of lines that need to be covered by units tests vary from shop to shop. Some shops take a strict approach requiring a 100% coverage. Most shops are not as stringent. For many shops an acceptable level of coverage is to make sure that all business rules and algorithmic code is covered as well as data initialization functions such as object constructors.
Automatic code generation is a common practice among many enterprises for creating simple data objects. Thus, some shops will forego testing setters and getter in data objects trusting that such validation will be exercised in other areas of the code.
The two most important items are that an enterprise have a reasonable, measurement-based code coverage policy in force, and that developers support the policy before checking any code into a repository branch exposed to the CI/CD process.
Putting It All Together
The days of testing being the sole responsibility of the QA department have come to an end. There is simply too much complex code that needs to work its way through the CI/CD pipeline. The developer is the person best equipped to react efficiently to remedying errors. Studies show time and time again, that the further testing moves away from the developer, the more expensive testing activity becomes. The rule of thumb at mabl is if you write it, you test it. The motto really is, test early, test often, and automate.
Automated testing is the bedrock of the CI/CD pipeline. The Development Phase is the first step in the CI/CD deployment process. However, it is not the only step. The next phase of testing in the Development Phase of CI/CD process is Local UI Testing, which we’ll examine at in detail in an upcoming installment.
See how mabl can help you automate testing throughout the entire CI/CD pipeline. Start your two week free trial today!




